记号
$\mu$通常表示总体的均值,$\bar{x}$通常表示样本的均值。$\sigma^2$表示总体的方差,方差的平方根$\sigma$表示总体的标准差。
方差
离散随机变量的方差公式如下:
$$
\operatorname{Var}(X)=\sigma^{2}=\frac{1}{N} \sum_{i=1}^{N}\left(x_{i}-\mu\right)^{2}
$$
但是如果总体数据太多,我们需要使用样本方差来估计总体方差,样本方差的公式如下:
$$
s^{2}=\frac{1}{n-1} \sum_{i=1}^{n}\left(x_{i}-\overline{x}\right)^{2}
$$
这里需要注意的是,因为样本集中的样本偏差很可能变小了,样本方差总是偏向于低估总体方差,所以这里我们要除以$n+1$来略微的修正样本方差来估计总体方差。
标准差
标准差总是方差的平方根,类似的我们可以得到,总体的标准差为:
$$
\sigma = \sqrt{\sigma^2}
$$
而样本的标准差为样本方差的平方根:
$$
s = \sqrt{s^2}
$$
但是需要注意的是,在方差中$s^2$是一个很好的$\sigma^2$的估计量,但是在标准差中,$s$并不$\sigma$的无偏估计量。
标准差有很好的的性质,因为标准差的单位与样本的单位相同,这就给了标准差更好的解释性。
随机变量
随机变量一般以大写字母表示。随机变量在不同的条件下由于偶然因素影响,其可能取各种随机变量不同的值,具有不确定性和随机性,但这些取值落在某个范围的概率是一定的,此种变量称为随机变量。随机变量可以是离散型的,也可以是连续型的。
随机变量是概率分布的基础。
概率密度函数
在随机变量的基础上我们可以定义概率密度函数(Probability density function,PDF)。我们日常所说的概率的含义其实是概率密度函数下方的某个区间的面积,为了达成这个目标,我们定义概率密度函数下方的面积的和一定为1。
概率密度函数与累积分布概率的关系如下:对于一维实随机变量X,设它的累积分布函数是$F_X(x)$。如果存在可测函数$f_X(x)$,满足:
$$
\forall-\infty<a<\infty, \quad F_{X}(a)=\int_{-\infty}^{a} f_{X}(x) d x
$$
那么X 是一个连续型随机变量,并且$f_X(x)$是它的概率密度函数。这个公式同样适用于离散的情况,只不过需要将积分改成求和的形式。
期望值
期望值通常使用$E(X)$来表示,在概率论和统计学中,一个离散性随机变量的期望是试验中每次可能的结果乘以其结果概率的总和。换句话来说期望值就是该变量输出值的加权平均。那么离散随机变量的期望公式为:
$$
\mathrm{E}(X)=\sum_{i} p_{i} x_{i}
$$
其中$x_i$为离散变量X可能的取值,$p_i$为离散变量X取值为$x_i$的概率。相似的,连续随机变量的期望的公式如下:
$$
\mathrm{E}(X)=\int_{-\infty}^{\infty} x f(x) \mathrm{d} x
$$
期望有以下性质:
- 期望值E是线性函数:
$$
\mathrm{E}(a X+b Y)=a \mathrm{E}(X)+b \mathrm{E}(Y)
$$
- 在一般情况下,两个随机变量的积的期望值不等于这两个随机变量的期望值的积。只有在一种情况下成立,就是这两个随机变量的协方差为0,也就是说这两个变量不相关,这是我们可以使用公式:
$$
\mathrm{E}(X Y)=\mathrm{E}(X) \mathrm{E}(Y)
$$
- 我们还可以通过期望值来求变量的方差:
$$
\operatorname{Var}(X)=\mathrm{E}\left(X^{2}\right)-\mathrm{E}(X)^{2}
$$
二项分布(Binomial distribution)
在概率论和统计学中,二项分布(Binomial distribution)是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为$p$。
一般的,如果随机变量X服从参数为n和p的二项分布,我们记$X \sim B(n, p)$。而n次试验中正好得到k次成功的概率由一下公式给出:
$$
f(k ; n, p)=\operatorname{Pr}(X=k)= \mathrm{C}^n_k p^{k}(1-p)^{n-k}
$$
为了有一个感性的认识,下面是一幅$n=6, p=0.5$时的二项分布以及其正态近似。(图片出自wikipedia)
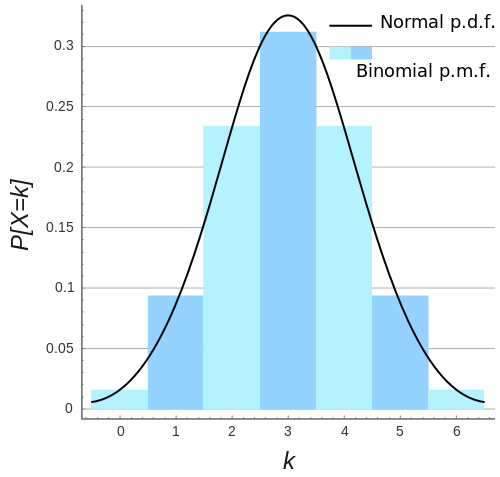
二项分布的期望值与方差
如果$X \sim B(n, p)$(也就是说,X是服从二项分布的随机变量),那么X的期望值为
$$
\mathrm{E}[X]=n p
$$
方差为:
$$
\operatorname{Var}[X]=n p(1-p)
$$
二项分布与正态分布的关系
如果n足够大,那么分布的偏度就比较小。在这种情况下,如果使用连续性矫正,那么二项分布$B(n, p)$有很好的近似正态分布$\mathcal{N}(np, npq)$。这种近似应该在$n > 20$的情况下使用,n越大近似越好,另外p不接近0或者1时更好。另外在做这种近似的时候我们希望$np>5$并且$npq>5$。
泊松分布(Poisson distribution)
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数等等。
我们先定义随机变量X,若变量X服从参数为$\lambda$的泊松分布,我们记为$X\sim \mathrm{P}(\lambda)$,这个泊松分布的累积概率函数(概率质量函数)为:
$$
P(X=k)=\frac{e^{-\lambda} \lambda^{k}}{k !}
$$
泊松分布的参数$\lambda$是单位时间(或单位面积)内随机事件的平均发生率。
泊松分布的性质:
- 泊松分布的期望与方差都相同,为其参数$\lambda$:
$$
E(X)=V(X)=\lambda
$$
- 两个独立且服从泊松分布的随机变量,其和仍然服从泊松分布:
$$
X+Y \sim \mathrm{P}\left(\lambda_{1}+\lambda_{2}\right)
$$